Jeśli miałbym wybrać tylko jedną rzecz, bez której już dzisiaj nie wyobrażam sobie zarówno programowania, jak i uruchomienia aplikacji na produkcji, to zdecydowanie byłby to system zbierania metryk i monitoring aplikacji.
TL;DR Metryki i monitoring – „a na co to komu?” i jak to łatwo uruchomić na początek na lokalnym środowisku
Ogólnie o monitoringu i metrykach
Jeśli kiedykolwiek zdążyło Ci się dodawać logi do aplikacji, które zawierają mierzony czas albo ilość przetworzonych elementów to właśnie doskonałe przykłady miejsc, które mogą i powinny być metrykami.
Rodzaje metryk
Każda aplikacja może eksportować różnego rodzaju metryki, wśród których można wyodrębnić następujące grupy:
- metryki niskopoziomowe (np. ilość wolnego miejsca na dyskach, obciążenie procesorów, ilość wolnej pamięci itp)
- statystyki jvm (np. statystyki poszczególnych obszarów pamięci, ilości wątków, aktywności GC)
- metryki techniczne (np. czasy odpowiedzi i ilości wywołań endpointów api, statystyki kodów odpowiedzi api, statystyki puli połączeń do bazy danych itp)
- metryki biznesowe (np. ilość aktywnych użytkowników, ilość zamówień)
Elementy systemu monitorowania
Na początek, dla uproszczenia przyjmijmy, że każdy system monitoringu aplikacji składa się tylko z jakiegoś sposobu wizualizacji i przetwarzania metryk oraz bazy danych do ich przechowywania (najczęściej typu „time series„).
W odniesieniu do wizualizacji to zdecydowanym standardem dla opensource jest Grafana i na niej skupimy się w dalszej części.
Natomiast najczęściej używanymi źródłami danych metryk są:
- usługi chmurowe (np. AWS CloudWatch, AWS Timestream, Azure Monitor/Application Insights, Google Stackdriver)
- komercyjne usługi monitoringu (np. Datadog, Dynatrace, New Relic, Splunk / SignalFX)
- samodzielnie zarządzane bazy danych metryk (np. Prometheus / Thanos, InfluxDB, Graphite, OpenTSDB, Akumuli)
Polecam sprawdzić bardzo imponującą, pełną listę wspieranych źródeł danych dla grafany. Poza wtyczkami wyróżnionymi na oficjalnej stronie istnieje wiele dodatków utrzymywanych przez społeczność. Znajdziesz tam większość mniej lub bardziej popularnych baz danych (np. dla Redis czy Google BigQuery).
W zależności od potrzeb można w większości przypadków łatwo podmieniać lub integrować metryki z wielu baz danych. Korelacja danych z różnych źródeł dostarcza często nowych informacji i pozwala na wyciągniecie dodatkowych wniosków.
Jednym z najbardziej popularnych rozwiązań opensource dla monitoringu jest Prometheus, który wraz z Grafaną stanowią bardzo dobraną parę. Taki zestaw zaraz przetestujemy.
Mity o Prometeuszu
Zbieranie metryk przez system monitoringu może się odbywać na dwa sposoby:
- push – monitorowana aplikacja wysyła własne metryki do systemu monitorowania
- pull – system monitorowania na podstawie reguł potrafi wykryć aplikacje i sam pobiera metryki
Prometheus jest systemem monitoringu opartym o metodę pull. Przez ten fakt jest czasem uważany za „dziwny”, ponieważ zdecydowana większość konkurencji przenosi odpowiedzialność za wysyłanie metryk na obiekt monitorowany.
Jak każde podejście ma to swoje wady i zalety:
Zalety
- doskonałe rozwiązanie dla healthcheck’ów
- można stwierdzić czy cel monitoringu jest aktywny
- informacja w jednym miejscu o statusie wszystkich instancji
Wady
- problemy z monitorowaniem krótko żyjących procesów (częściowe rozwiązanie – push gateway)
- problemy ze skalowaniem
- monitoring musi wiedzieć o wszystkich monitorowanych hostach
Mitów na temat Prometeusza jest sporo, ale to temat na osobny, dość okazały wpis.
Do dzieła – Monitoring aplikacji Spring Boot z wykorzystaniem Micrometer, Prometheus i Grafana
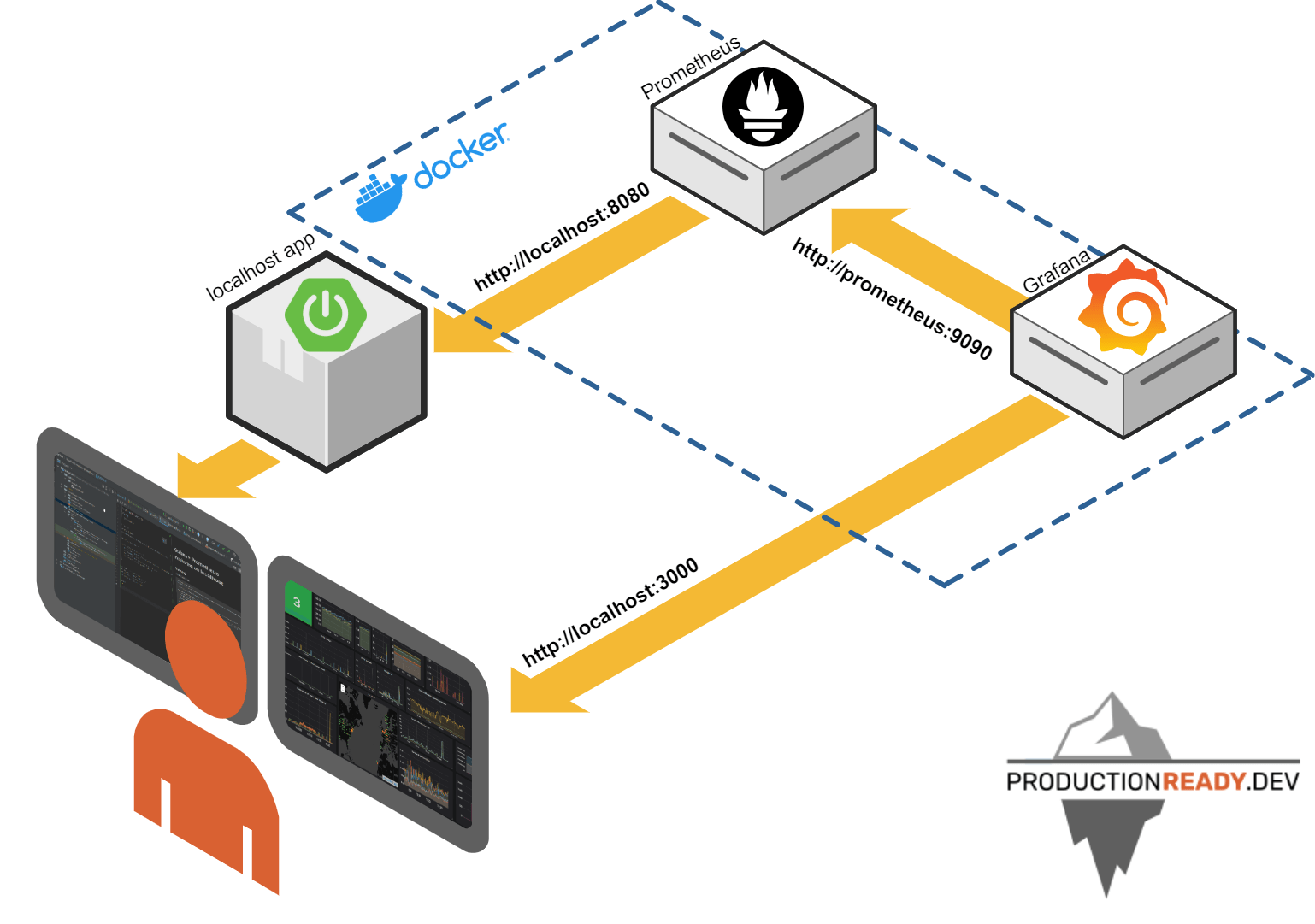
Dla uproszczenia załóżmy, że mamy aplikację Spring Boot, którą chcemy monitorować. Przygotowałem dla Ciebie przykład, który możesz użyć lub dodać analogiczną obsługę dla własnej aplikacji.
Dla mojego przykładu wszystko, co musisz zrobić to sklonować repozytorium:
git clone https://github.com/production-ready/metrics-ready-sandbox-app.gitNastępnie uruchom lokalnie aplikację w standardowy sposób – np. bezpośrednio w IDE lub używając wtyczki maven:
cd metrics-ready-sandbox-app && ./mvnw spring-boot:runUżywając dla testów naszej aplikacji, możesz pominąć poniższy akapit lub odnaleźć podane niżej elementy w przykładzie.
Dodanie obsługi i eksportu metryk dla własnej aplikacji Spring Boot
Jeśli zdecydowałeś się na dodanie obsługi dla własnej aplikacji, to sprawa wygląda równie prosto. Wystarczy dodać dwie zależności [zobacz dokumentację] – Spring Boot’owy actuator i dostarczyć implementacji rejestru metryk Micrometer [już teraz zapraszam na kolejny wpis, w którym omówimy dokładniej Micrometer – bądźcie czujni ;)].
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
<scope>runtime</scope>
</dependency>Dodatkowo musisz dodać konfigurację application.properties (lub oczywiście dowolny inny sposób dostarczania konfiguracji w Spring Boot, który preferujesz) pozwalającą na wyeksponowanie metryk w aplikacji. Domyślnie jest udostępnione wszystko przez jmx, natomiast przez http jest udostępnione tylko info i health ze względu na potencjalnie wrażliwe dane.
management.endpoints.web.exposure.include=info,health,prometheusUruchomienie zbierania metryk aplikacji
Przygotowałem dla Ciebie prosty projekt na Github zawierający podstawową konfigurację dla Prometheusa i Grafany. Najważniejszym elementem jest plik docker compose za pomocą którego uruchomisz całą przykładowy zestaw.
Pobierz repozytorium na swój komputer:
git clone https://github.com/production-ready/localhost-metrics-prometheus.gitNastępnie będąc w głównym katalogu projektu wszystko, co musisz zrobić to uruchomienie docker-compose:
cd localhost-metrics-prometheus && docker-compose up -dZakładam, że korzystałeś już z docker’a oraz docker-compose. W przeciwnym wypadku tutaj znajdziesz instrukcje jak zainstalować docker oraz docker-compose
W ten sposób uruchomimy Prometheusa i Grafanę jako osobne kontenery dockera. Cały zestaw działa na osobnej sieci typu bridge, jednocześnie posiadając dostęp do hosta dzięki zastosowaniu dość przydatnego tricku w postaci użycia adresu host.docker.internal.
To rozwiązanie działa świetnie na Mac i Windows, jednak na Linux może istnieć potrzeba dodania dodatkowego mapowania w docker-compose (zostawiłem zakomentowane na taką okoliczność):
extra_hosts:
- "host.docker.internal:host-gateway"Daj znać w komentarzu, jeśli znasz lepszy sposób, który działa na wszystkich platformach tak samo.
Rzut oka na konfigurację
Repozytorium zawiera również podstawową konfigurację, pozwalającą zobaczyć od razu efekt całej pracy:
- konfiguracja Prometeusza pobierająca metryki z aplikacji uruchomionej na porcie 8080 i wystawiającej metryki pod adresem /actuator/prometheus (standardowy port, standardowy endpoint dla Spring Boot)
- dodane domyślne źródło danych dla Grafany – nasz Prometheus z kontenera obok
- dodany domyślny dashboard dla metryk jvm który jest oparty na najpopularniejszym dashboardzie dla actuatora w katalogu Grafany
Po uruchomieniu dostarczonego docker-compose powinny bez problemu móc otworzyć się w przeglądarce dwie zakładki:
Sprawdzamy czy działa
- Prometheus – http://localhost:9090/
- Grafana – http://localhost:3000/ (musisz się zalogować na domyślne admin/admin i zmienić hasło)
Jeśli aplikacja Spring Boot jest uruchomiona, to sprawdźmy w pierwszej kolejności w Prometheus, czy połączenia działa i metryki są zbierane. W tym celu przejdź do zakładki w menu Status/Targets
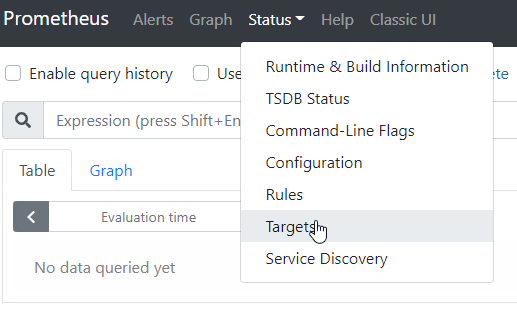
Tutaj możemy zweryfikować czy Prometheus nie ma żadnych przeszkód w pobieraniu metryk z naszej aplikacji.
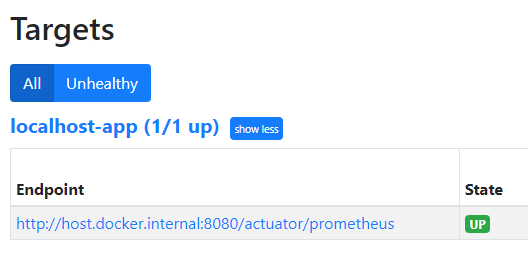
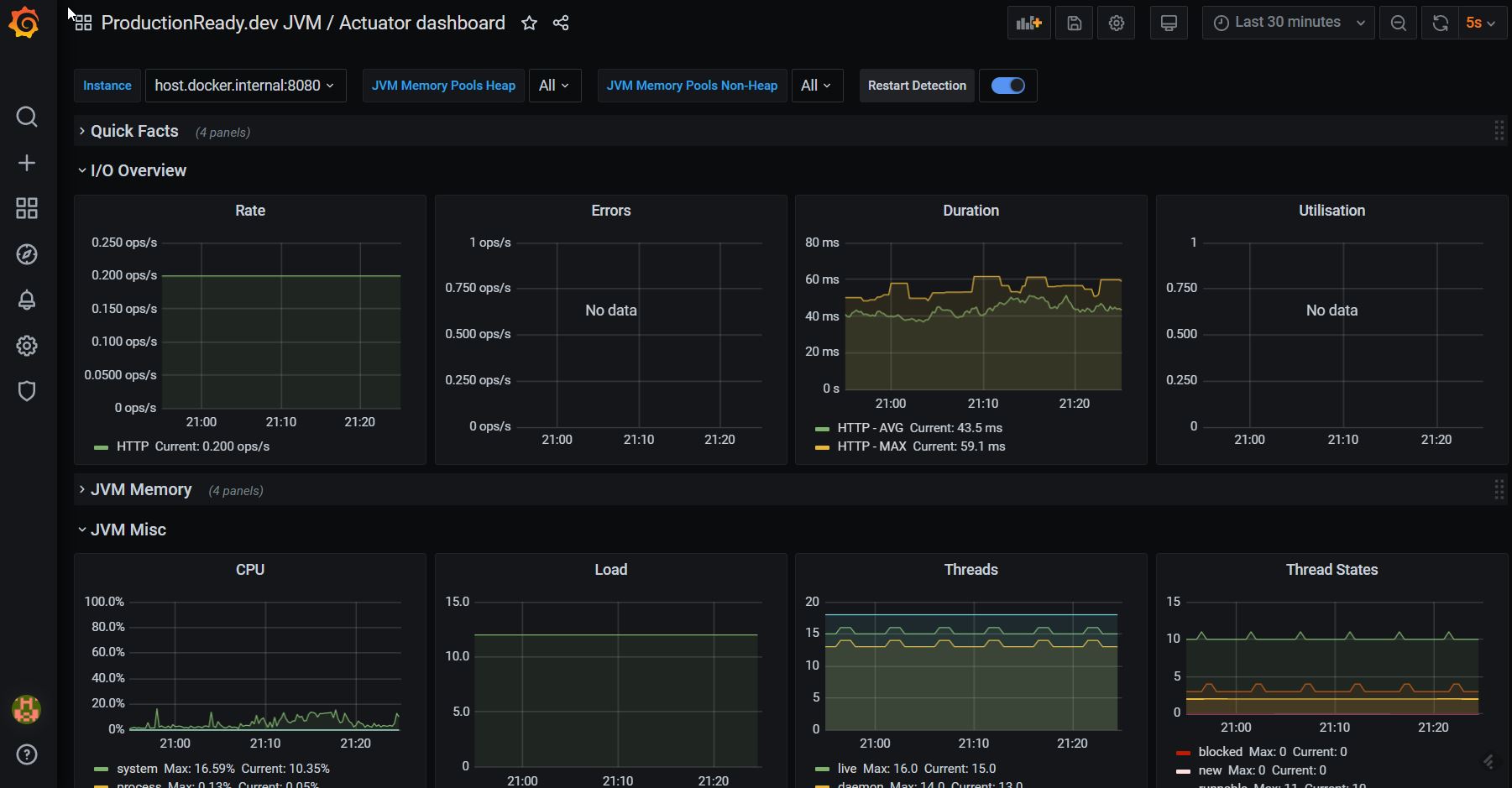
W tym momencie można przejść do Grafany, gdzie powinieneś zobaczyć ekran z dostępnym dashboardem [1].

Po kliknięciu powinieneś zobaczyć ekran ze świeżo zebranymi, podstawowymi metrykami prosto z Twojej aplikacji.
Podsumowanie
Posiadanie monitoringu na lokalnym środowisku to doskonały wstęp, a także wartościowe uzupełnienie rozwiązania produkcyjnego.
Pierwsza zasada optymalizacji, której polecam się trzymać, brzmi – nie optymalizuj, jeśli nie mierzysz. Monitoring aplikacji otwiera drogę do wielu eksperymentów, a także często pozwala na wychwycenie błędów na bardzo wczesnym etapie. Obserwowanie aplikacji testowanej lokalnie pozwala lepiej rozumieć jej działanie.
W kolejnych wpisach omówimy sposoby dodawania kolejnych metryk by oprócz typowo technicznych wartości związanych z pracą jvm, dodawać i monitorować dowolny aspekt działania aplikacji.
Daj znać w komentarzach czy to Twoim zdaniem lepiej wklejać we wpisie te kawałki kodu i konfiguracji, czy lepiej dodawać szczegółowe odnośniki do github [i koniecznie zapisz się do newslettera, by mieć pewność, że nie przegapisz kolejnego wpisu].


Super, dobrze się czyta! Jak dla mnie najlepsze rozwiązanie to wklejanie we wpisie konfiguracji oraz odnośniki do githuba dodatkowo. Czekam na kolejne wpisy 😉
Dzięki Paweł za opinię i miłe słowo!
Fajny post panowie. Ja jedyne co bym zrobił to obdarł bym część aplikacyjną z magii springa. I pokazał że zrobienie tego „by hand” z pomocą micrometer to też 10 minut:
public PrometheusMeterRegistry create() { var prometheusRegistry = new PrometheusMeterRegistry(PrometheusConfig.DEFAULT); new ClassLoaderMetrics().bindTo(prometheusRegistry); new JvmMemoryMetrics().bindTo(prometheusRegistry); new JvmGcMetrics().bindTo(prometheusRegistry); new JvmThreadMetrics().bindTo(prometheusRegistry); new ProcessorMetrics().bindTo(prometheusRegistry); new LogbackMetrics().bindTo(prometheusRegistry); new FileDescriptorMetrics().bindTo(prometheusRegistry); new UptimeMetrics().bindTo(prometheusRegistry); new ProcessMemoryMetrics().bindTo(prometheusRegistry); return prometheusRegistry; }Tyle zazwyczaj starcza dla dashboardu typu: https://grafana.com/grafana/dashboards/4701
plus oczywiscie potrzebujemy wystawic endpoint z metrykami ale to też kilka linijek.
Super Damian, Dzięki! Świetnie, że poruszyłeś ten temat, bo właśnie się tworzy kolejny wpis o micrometer, w którym będzie więcej takich szczegółów. Zdecydowanie tak jak piszesz, tam nie ma żadnej magii, można to zdecydowanie samemu dodać.